
LLMを活用してシンボリックGame AIを構築する研究の紹介 (2024年度人工知能学会全国大会)
こんにちは、機械学習Gの加納です。
KLabでは、ゲームエンジニアと機械学習エンジニアが協力し、新しいゲームAIの研究を進めています。 その成果の一つとして、2024年度人工知能学会全国大会(第38回)にて、「LLMを活用したシンボリックGame AIの構築」という研究を発表しました。
この記事では、その研究内容を詳しくご紹介いたします。
研究の背景
エンターテイメントゲームでは、ユーザーが楽しめるようなゲーム体験を提供することが大きな目標となっています。そのため、ゲーム内のノンプレイヤーキャラクター(NPC)もゲームデザイナーの意図を反映したキャラクター性を持つことが求められます。本研究では、NPCがデザイナーの意図に従うことを「アライメント」と呼んでいます。
現在、ゲームAIの開発には「シンボリックAI」という手法が広く使われています。この手法では、ルールベースの処理を組み合わせてNPCの行動を制御し、開発者が直感的にNPCの振る舞いを設定することができます。しかし、全ての行動パターンを手作業で実装する必要があるため、多数のNPCを作成する際には大変な労力がかかります。
一方、深層強化学習を用いたゲームAIの研究も進んでいます。この手法を用いると、NPCが自ら学習し、より汎用的で柔軟な振る舞いを身につけることができます。
例えば、先行研究「Reward design with language models(Kwon, Minae, et al.)」では、エージェントの行動ログを自然言語に変換し、LLM(大規模言語モデル)で「エージェントが個性を表現できているか?」をYes/Noで評価し報酬を決定するという手法が提案されました。この研究により、LLMの一般的な知識を活用して、個性や役割のアライメントが可能であるという結果が得られています。
しかし、深層強化学習を実際の開発現場に応用するには以下のような課題があります。
- 学習結果の制御が難しい:意図しない振る舞いをすることがあり、開発者が望む結果を得るのが難しい。
- 計算リソースの必要性:深層モデルを動かすには十分な計算リソースが必要であり、コストが高い。
- 環境整備のコスト:AIの学習環境を整える必要があり、開発フローへの導入コストが高い。

提案手法の概要
そこで今回は、LLM(大規模言語モデル)を活用してキャラクターの行動を再現する評価関数を作成し、シンボリックAIの上で動作させる手法を提案しました。
この手法により、従来のゲームAI開発ではエンジニアがAIの仕様書から手作業で行動を設計していた作業を自動化できます。 その結果、エンジニアはより細かい挙動の制御に集中でき、ゲーム開発の効率が向上することを目指しています。
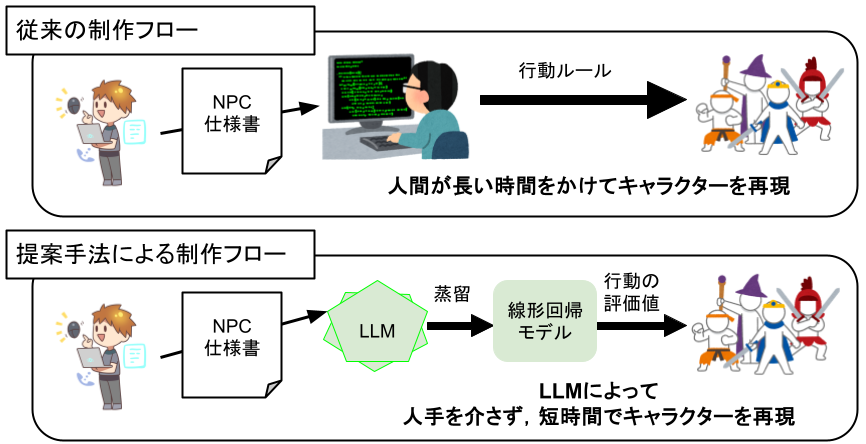
シンボリックAI
提案手法の詳細を説明する前に、今回の研究で使用したシンボリックAIについて説明します。
NPCの状態表現
NPCの行動を機械学習で扱えるようにするためには、人間が理解し設計できる状態の表現が必要です。
そこで、NPCの状態を複数の「条件」の真偽を並べた2値ベクトルで表現することにしました。
ここでの「条件」とは、シンボリックAIにおける記号のことを指します。例えば、「剣を持っている」、「アイテムを持っている」、「HPが50%以上」などTrue/Falseで評価できるものが条件となります。
2値ベクトルを使用することで計算の高速化が可能となり、リアルタイムでのゲームプレイがよりスムーズになるというメリットも得られます。

NPCの行動定義
NPCの行動は「前提(満たすべき条件)」と「結果(達成される条件)」で定義されます。例えば、「剣で攻撃する」という行動は、以下のように定義できます。
- 「前提」:「剣を持っている」かつ「敵が近い」
- 「結果」: Not「敵が近い」
NPCの状態が「前提」を満たしている場合、その行動を実行することができます。
また、「行動後の状態」は「現在の状態」が「行動の結果」を満たす状態に遷移するように表現できます。 つまり、「現在の状態」と「行動の結果」によって、「行動後の状態」が一意に定まります。 「剣で攻撃する」の例では、「行動後の状態」は「現在の状態」の「敵が近い」がFalse(0)になった状態に遷移しています。
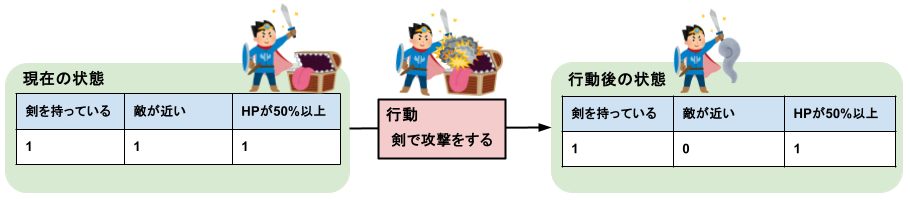
このようなシンボリックAIを使用することで、ゲーム内で実際に行動を行わずに、行動による状態遷移データを擬似的に作成することが可能です。
ゲーム実行時における条件の真偽評価や剣で攻撃するプログラムは人間が開発します。これらを人間が作成・制御することによって、開発者が自由にNPCの見た目上の動きなどを調整できるように設計しています。
この提案手法はNPCの設計図があれば適用可能なので、ゲーム内でデータを収集する必要がなく、プログラムの実装にも依存しないため、開発の初期段階から適用することができます。 ゲーム開発と共にNPCの調整やアップデートが行なえることは産業応用上重要ですが、この提案手法はその点をカバーしています。
提案手法
LLMを活用してキャラクターを再現するような行動評価関数を作成して、 先に説明したシンボリックAIの上で動作させる手法を提案しました。提案手法の要素は3つに分けられます。
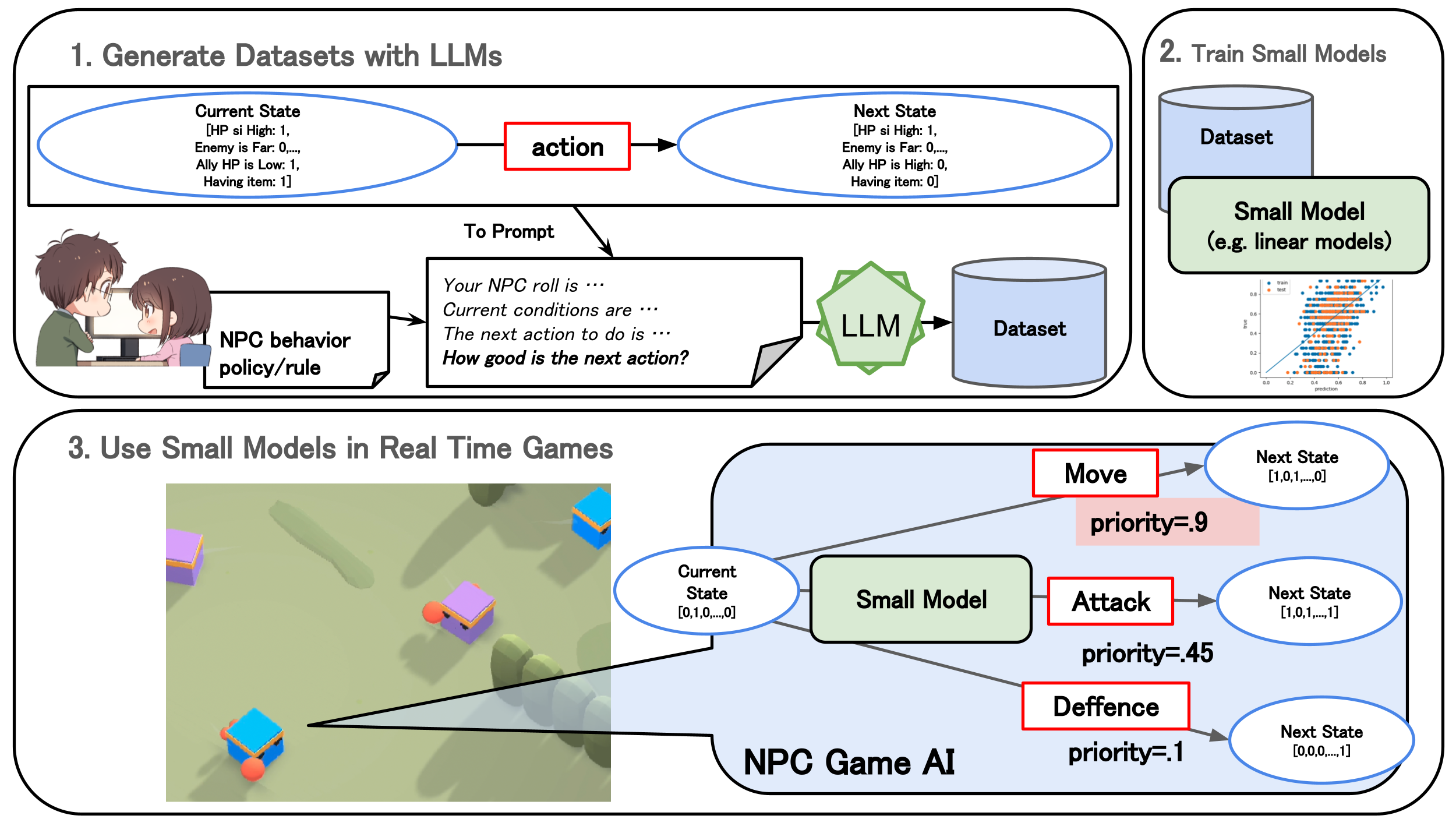
LLMを用いたデータセットの作成
1. 状態遷移データの生成
状態遷移データをランダムに生成します。具体的には、「現在の状態、行動、行動後の状態」を生成しています。 まず、ランダムに01ベクトルを生成することで「現在の状態」を表現します。 次に、生成した「現在の状態」から実行可能な「行動」をランダムに選択します。 「行動後の状態」は「現在の状態」と「行動」から計算します。
2. NPCの仕様文書
NPC仕様文書のテキストデータをLLMに入力するテキストとして使用します。 NPC仕様文書とは、ゲームデザイナーが定義したNPCのキャラクター性や行動ルールを記述した文書です。
3. 行動をLLMで複数観点で3段階評価
1と2で生成したデータを元に、LLMに入力するプロンプトを作成します。 このプロンプトによって、現在の状態における行動を複数の観点で3段階で評価します。
評価は良いもの順に、Excellent, Average, Poorと設定しています。プロンプト間での評価の一貫性を保つために、100点満点ではなく、3段階評価にしています。
評価観点は例えば、キャラ再現度、敵への効果、味方との協力などです。1つ1つの評価は3段階ですが、複数の観点を用意して最後に合算することで、最終的な評価の粒度を上げるように工夫しています。
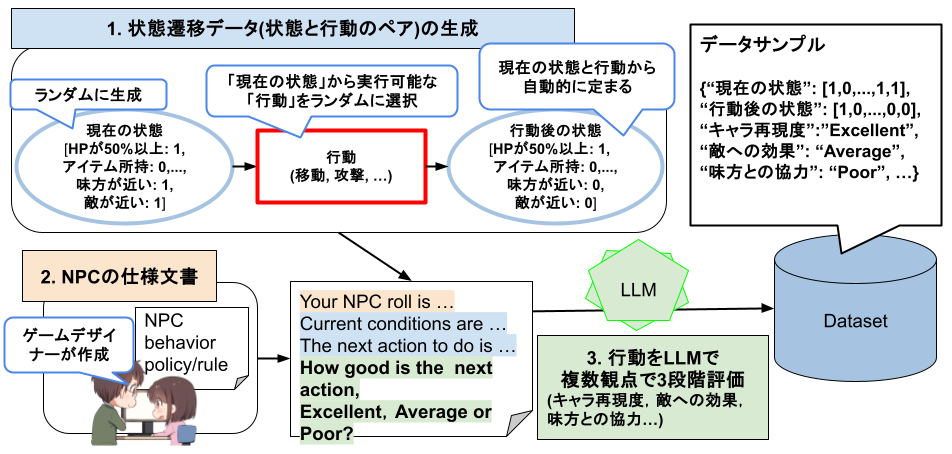
最終的には、以下の情報を持つデータセットを作成します。
- 現在の状態と行動後の状態の01ベクトル
- 各観点の評価値(Excellent、Average、Poor)
このようにして、さまざまな状態における行動の評価データを大量に生成することで、NPCの行動評価関数を学習するためのデータセットを作成します。
意思決定関数の蒸留
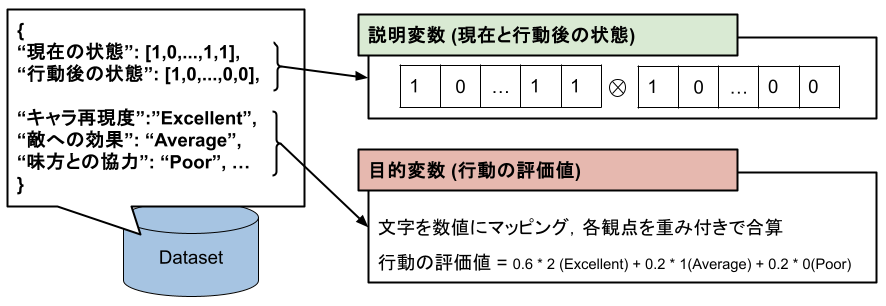
作成したデータセットを使用して、線形回帰モデルを構築します。このモデルは、「状態遷移」から「行動の評価値」を推定するために使用されます。
- 説明変数: 現在と行動後の状態の01ベクトルを連結したベクトル
- 目的変数: 行動の評価値(Excellent、Average、Poor)を数値にマッピングし、各観点を重み付けして合算した値
- キャラ再現度の重みを大きくすることで、キャラクター性を重視した行動を選択するようにします。
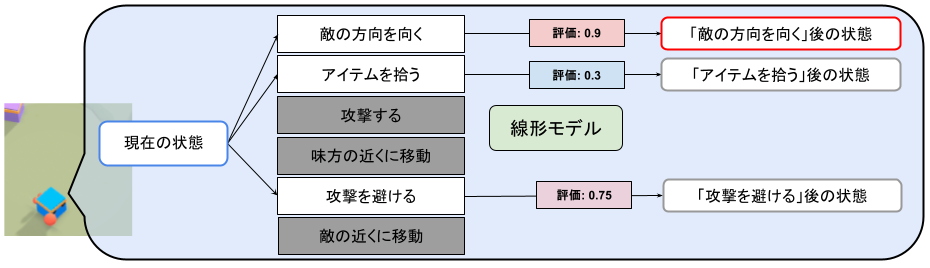
シンボリックAI上での意思決定
シンボリックAI上では、以下の手順で行動のキャラ再現度を評価し、最高評価の行動を実行します。
行動評価のモデルは線形モデルという小さい機械学習モデルを使用しているため、計算コストが低く、リアルタイムでの意思決定が可能です。
- 「条件」を評価して、現在の状態を取得します。
- 前提を満たしている(つまり実行可能な)行動の評価値をモデルで推定します。行動後の状態は現在の状態と行動の結果から計算されます。
- 推定評価値が最も高い行動を選択します。
実験の設定
-
実験環境
- Unityで作成されたドッジボールゲームの環境を使用しました
- ゲームルール:
- 各チームは4体のキャラクターで構成されています。
- フィールドに落ちているボールを拾い、相手に向かって投げます。
- キャラクターはボールが2回当たるとゲームオーバーになります。
- 相手チームを全滅させると勝利となります。
-
検証キャラクター
-
今回の研究では、実験として以下の3つのキャラクターを用意しました。この3キャラクターの再現を提案手法で実現できるかを検証しました。
-
攻撃型 (近接攻撃型)
詳細
敵が多い場所に入っていって、積極的に攻撃に参加する攻撃型キャラクター。 ボールを積極的に拾いながら、敵に近距離攻撃を与える。 敵に攻撃ができる時は、ボールを積極的に投げていく。 危険な時は攻撃を回避する。 -
バランス型 (近接遠距離両方)
詳細
攻撃もしつつ、危険な時は攻撃を回避し、味方のサポートも行うバランス型のキャラクター。 できるだけチームの勝利に貢献するために、いろんな動きを柔軟に行う。 攻撃ができそうな時は攻撃する。 -
サポート型 (遠距離攻撃型)
詳細
危険な味方の攻撃をサポートするキャラクター。 敵が多い場所にはあまり近付かず、できるだけ離れたところからボールを拾って、敵を攻撃する。 危険な時は攻撃を回避する。敵が居て、攻撃ができる時は攻撃する。修正版 * サポート型はプロンプトを修正して実験をやり直しています。(後述)
危険な味方の攻撃をサポートするキャラクター。 敵が多い場所には極力近づかず、ボールを拾い、できるだけ遠くから敵を攻撃しましょう。 危険なときは攻撃を回避します。 このNPCは敵を探索し発見した場合、近づかずその場で攻撃するだけです。
-
-
条件・行動
-
今回は26種類の条件と19種類の行動を用意しました。
-
条件の例としては、「敵/味方が近くにいる」「ボールを持っている」、「敵の方向を向いている」、「最寄りの味方のHPが低い」などがあります。近くにいるやHPが低いなどの定義は、実際のゲームに合わせて定義しました。
-
行動の例としては、「ボールを投げる/避ける」,「味方/敵の近くに移動する」,「最寄り/2番目に最寄りのボールを取りに移動する」などを定義しました。ボールや敵までのルートはUnityのNavMeshAgentというルート探索ライブラリを使用して計算しています。
-
-
データセットについて
- LLMはGPT-3.5-turboを使用しています。
- 各キャラクターについて、約1170の学習用データサンプルを生成しました。
- データの作成が完了するには約20分ほどかかりました。
- 作成時に使用した行動評価用のプロンプトは以下の通りです。
(システムプロンプトはLLMの振る舞いを定義する文章、ユーザプロンプトは人間が入力する文章です。) システムプロンプト ユーザープロンプト プロンプト詳細
実験では英語で記述していますが、日本語訳しています。プロンプトはシステムプロンプトとユーザプロンプトの2つを使用しています。
# これは_非常に重要なタスクですので、集中して解決してください。
あなたはアクションゲームのゲームデザイナーであり、特定のNPCの行動の質を評価し、協力、仕様への忠実度、自己利益、味方への利益、敵への影響、自身の安全、味方の安全の各側面において適切な行動をNPCに割り当てます。
NPCは、味方、自身のヒットポイント、位置、仕様条件などの状況に応じて適切な行動をとる必要があります。
与えられた状況に基づいて自己判断をせずに、厳密な評価と決定を行ってください。
まずNPC、ゲーム状況、NPCが目指している状態、そして次に取るべき行動が提示されます。
回答では、目標と仕様に基づいて焦点を当てるべき条件をまず決定してください。その後、条件を確認し、次の行動が適切かどうかを検証します。
評価の理由を考え、深呼吸してから評価を検証し、最終的な評価を行ってください。
評価指標を3段階の[Excellent, Average, Poor]で評価してください。各評価指標に対してこの3つの評価値のいずれかを必ず割り当ててください。空欄やNaNフィールドは許可されません。# 出力フォーマット(<EVALUATION>部分を3段階の[Excellent, Average, Poor]で評価します。できるだけこの3段階で評価してください。もし不明な場合は、一般的なアクションゲームに基づいて推測してください。)
1. 理由: <各評価視点で確認する必要がある状況を考慮し、与えられた条件を確認します。その後、評価の理由を説明します。>
2. 検証: <先に考えた理由を検証し、修正が必要な点があれば修正します。>
3. 評価: # 評価のみを回答します。評価を空欄にしたり飛ばしたりすることは許可されません!
味方との協力: <EVALUATION>
NPC仕様への忠実度: <EVALUATION>
自己利益: <EVALUATION>
味方の利益: <EVALUATION>
敵への影響: <EVALUATION>
自身の安全: <EVALUATION>
味方の安全: <EVALUATION>
# ゲームの説明
<ゲームの説明>
# NPC仕様
{npc_specification}# 現在の状況
{state_prompt}
# 次に取るべき行動
{next_action}
# 出力形式 (3段階で<EVALUATION>パートを評価します:[Excellent, Average, Poor]。できるだけこの3段階で評価してください。不明な場合は、一般的なアクションゲームに基づいて推測してください。)
1. 理由: <各評価視点で確認する必要がある状況を考慮し、与えられた条件を確認します。その後、評価の理由を説明します。>
2. 検証: <先に考えた理由を確認し、修正が必要な点があれば修正します。>
3. 評価: # 評価のみを回答します。評価を4つの選択肢で必ず記入してください。評価の飛ばしや空白は許可されません!
味方との協力: <EVALUATION>
NPC仕様への忠実度: <EVALUATION>
自己利益: <EVALUATION>
味方への利益: <EVALUATION>
敵への効果: <EVALUATION>
自身の安全性: <EVALUATION>
味方の安全性: <EVALUATION>
結果
実験では、以下の点について検証を行いました。
Q1. 状況に応じた適切な意思決定が可能か
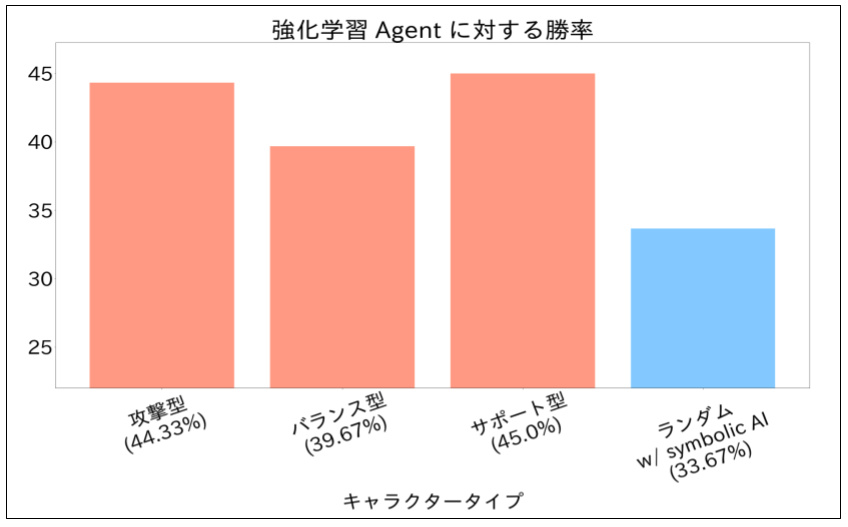
学習済みの強化学習エージェントとシンボリックAIとの間で300回の対戦を行いました。
勝率を比較することで、キャラの再現度に意思決定が偏ってしまう(ボールを避けるべきなのに他の行動を取る・明らかにボールを投げるべきなのに投げないなど)ことなく、基本的に状況に応じて適切な意思決定ができているかを検証しました。
比較対象のシンボリックAI
- 提案手法を使用した3つのキャラクター
- 実行可能な行動からランダムに選択するシンボリックAI
結果
- 提案手法の勝率はランダムな手法よりも高かった。(統計的に有意性あり)
- モデルがゲームルールを理解し、基本的に状況に応じた意思決定ができることが確認できました。
Q2. キャラクター仕様を再現した意思決定が可能となるか
この検証では、被験者5名にNPCの動作動画を提示し、動作NPCがどのキャラらしいかを予測してもらいました。
結果
- 攻撃型とバランス型については、被験者の予測したキャラクター型と実際のキャラクター型が一致する割合が高く、キャラクターの再現に成功したという結果が得られました。
- 一方で、サポート型に対して、サポート型らしいと予測した割合は低い結果となりました(20%)。
- サポート側はより攻撃型らしく見えてしまっていたようでした。
下の図は、それぞれのキャラクターに対する被験者の予測割合を示しています。 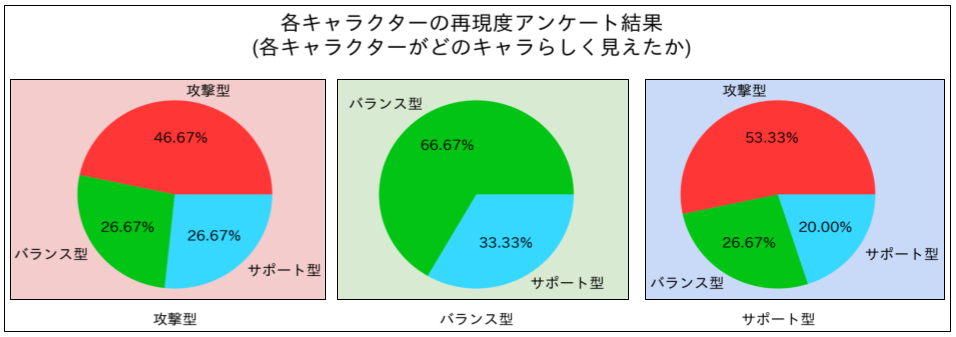
サポート型のキャラクターの再現に失敗した理由を考察しました。 その結果、サポート型のキャラクターは、ある特定の状態下で、攻撃型よりも敵の近くに移動する傾向があることがわかりました。(下図の赤字部分注目)
|
キャラクタータイプ
攻撃可能な敵まで |
攻撃型 | バランス型 | サポート型 | サポート型(修正後) |
|---|---|---|---|---|
| 中距離 | 63 | 0 | 150 | 0 |
| 長距離 | 119 | 0 | 0 | 0 |
この挙動のせいで、サポート型のキャラクターが攻撃型のように見えてしまった可能性があります。
サポート型のキャラクターの仕様文書を調べると、意図に合わない表現が含まれていたことも判明しました。
具体的には、"If there is an enemy and you can attack, attack."と命令形で攻撃を促すような表現がありました。
このサポート型のキャラクターの仕様文書を修正したところ問題が解消しました。 今手法では、プロンプトに本来の意図とのズレが生じないように注意する必要があると考えられます。
最後に実際に各キャラクターのプレイ動画を共有します。 青いキャタクターが提案手法によって動いていて、1試合で4対のキャラクターがすべて同じキャラクター型となっています。
紫色のキャラクターが強化学習エージェントによって動いています。
まとめ
今手法では、シンボリックAIとLLMを活用して、NPCの性格や役割を再現した行動の評価関数を作成する研究を紹介しました。 この手法では、人手でのアノテーションやゲーム内でのデータ収集は必要なく、プロンプトを使用してキャラクターの性格を再現することができます。 また、シンボリックAI上で動かすことができるため、開発現場での応用も容易です。
最近のLLMによる汎用的な知識を活用することにより、産業応用が行いやすいAIの開発が今後も模索できると考えています。 具体的には、LLMを他のシンボリックAI(例:ビヘイビアツリー)への活用や、キャラクター仕様とのアライメント精度を向上させるためのモデル学習や調整方法の開発が可能ではないかと思っています。 今後も、新しいAI技術を活用したゲームAIの研究を進めていきます!
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。