
EmscriptenからSSEとかpthreadを使って爆速にする
Webでとにかく高速に計算したい
やまだです。Webでとにかく高速な計算を行うために人生の何%かを使っています。
前回はJavaScriptから直接SIMD.jsを呼びましたが今回はEmscriptenを使用し、C言語からSIMD命令を呼び出してみます。
題材としては定番ですがマンデルブロ集合を使用します。
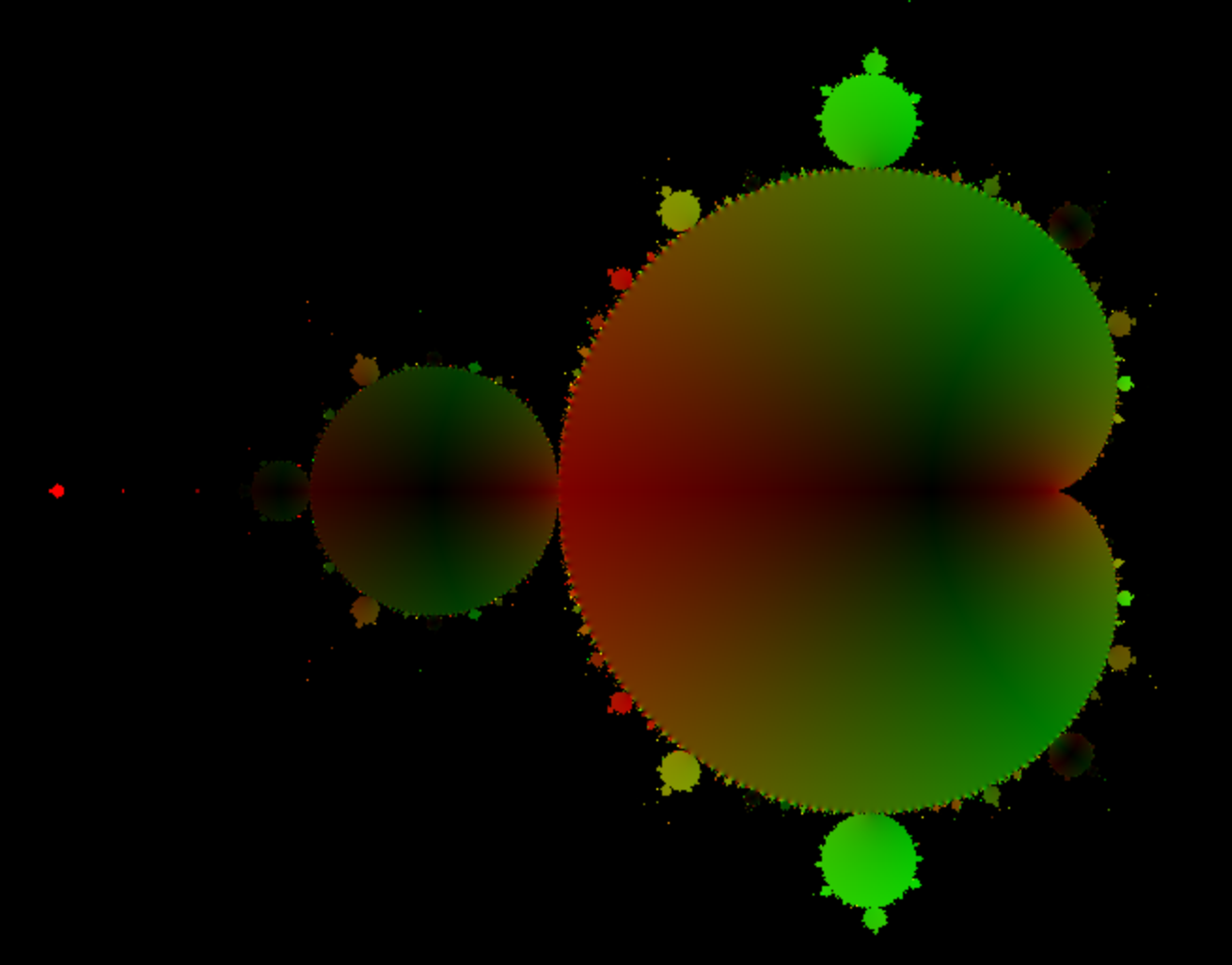
マンデルブロ集合は以下の漸化式で計算が可能でしばしば並列演算の課題としてとりあげられます。
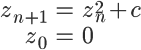
z は複素数なので実部と虚部をXY平面に表すと以下のようになります。
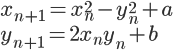
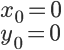
Emscriptenを使う
今回はWebでということでC言語のコードをJavaScriptコードにコンパイルするEmscriptenを使用します。
Emscriptenを使用するとasm.jsを利用した最適化をかけることができるため単純にJavaScriptで実装した時よりも高速になることがあります。
Emscriptenでは -O1 以降を指定するとasm.jsが有効となります。今回は -O3 を使用して計測しました。
Emscriptenでコンパイルすることを前提としてCでマンデルブロ集合を実装すると以下のようになります。
#define N (500)
void compute(int bufferLength)
{
for (int i = 0; i < N; i++)
{
for (int j = 0; j < bufferLength; j++)
{
float zx = zxBuffer[j];
float zy = zyBuffer[j];
zxBuffer[j] = zx * zx - zy * zy + cxBuffer[j];
zyBuffer[j] = 2.0 * zx * zy + cyBuffer[j];
}
}
}全ピクセルに対してN回ループする必要があるため非常に重い処理であることがひと目でわかります。
実行時間はマンデルブロ集合のループ計算を開始してからテクスチャ用のRGBバッファに変換するまでの時間を計測しています。
SSE: disabled
Thread: 1
Width: 1024
Height: 1024
PixelRatio: 2.0
Step: 500
Time : 3414msスレッドを使う
compute関数の内側のループはスレッドを使用して分割できそうですのでこちらに挑戦してみます。
Emscriptenはマルチスレッドライブラリであるpthreadを実験的にサポートしています。
コンパイル引数に-s USE_PTHREADS=1を加えることによりpthreadを有効にできます。
ただし、ECMAScriptのドラフト仕様であるSharedArrayBufferに依存しているため、2017年6月現在Firefox Nightlyでのみ動作します。
#define N (500)
#define NUM_THREADS (2)
// マンデルブロ集合を計算する
static void *compute(void *args)
{
THREAD_ARGS *threadArgs = (THREAD_ARGS *)args;
int min = threadArgs->min;
int max = threadArgs->max;
for (int i = 0; i < N; i++)
{
for (int j = min; j < max; j++)
{
float zx = zxBuffer[j];
float zy = zyBuffer[j];
zxBuffer[j] = zx * zx - zy * zy + cxBuffer[j];
zyBuffer[j] = 2.0 * zx * zy + cyBuffer[j];
}
}
return NULL;
}
// スレッドを作成する
static void create_threads(int bufferLength, pthread_t **threads)
{
for(int i = 0; i < NUM_THREADS; i++) {
// 分割する
int min = i * bufferLength / NUM_THREADS;
int max = (i + 1) * bufferLength / NUM_THREADS;
// スレッドを作成
pthread_create(threads[i], NULL, compute, (void *)get_thread_args(min, max));
}
}結果は以下のようになりました。
単一スレッドで実行した時に比べて1.7倍程度高速化できています。
計測環境はCPUコア数が2であったこともあり、4スレッドにしたとしてもパフォーマンス向上は体感できませんでした。
ですが、コア数がもっと多いCPUですと演算器の数の制限などはあるでしょうが、スレッド数を増やすことによりパフォーマンスが向上することが期待できます。
SSE: disabled
Thread: 2
Width: 1024
Height: 1024
PixelRatio: 2.0
Step: 500
Time : 1952msSIMDを使う
さて、もう一つの高速化の方法として1命令で複数の計算処理が可能なSIMD命令を使用してみます。
SIMD命令に対応しているブラウザでのみ動作します。
SIMDを使用するにはいくつか方法があります。
- LLVMの自動ベクトル化機能を使用する
- GCC/Clang固有のSIMD拡張を使用する
- IntelのSIMD拡張であるSSEを使用する
今回はSSEを使用します。
IntelのSIMD拡張はMMXやAVDなどがありますがEmscriptenはSSE1, SSE2, SSE3, SSSE3のみ対応しています。
SSEを使用するにはコンパイル時に-msseオプションを指定します。
SSEを使用する場合は128ビット幅の__m128を使用します。__m128には32ビットfloatが4つパックされています。
_mm_add_psや_mm_mul_psがSSE用の関数ですので演算にはこちらを使用します。
見ての通り_mm_add_psが加算、_mm_mul_psが乗算APIとなります。
公式リファレンスにアラインメントの指定なども書かれているので、こちらの指示に従った形でメモリ確保をする必要があります。
SSEは16ビットにアラインされたバッファが必要となるため、専用のaligned_allocでメモリを確保します。
ですがaligned_allocはEmscriptenでビルドすると関数が見つからずにエラーとなってしまったため、Emscriptenのbenchmark_sseで使用されているマクロを使用することにしました。
#define aligned_alloc(align, size) (void*)(((uintptr_t)malloc((size) + ((align)-1)) + ((align)-1)) & (~((align)-1)))
// 項zと定数cのバッファを確保する
static float *zxBuffer = NULL;
static float *zyBuffer = NULL;
static float *cxBuffer = NULL;
static float *cyBuffer = NULL;
static void alloc_bufers(int bufferLength)
{
zxBuffer = (float *)aligned_alloc(16, bufferLength);
zyBuffer = (float *)aligned_alloc(16, bufferLength);
cxBuffer = (float *)aligned_alloc(16, bufferLength);
cyBuffer = (float *)aligned_alloc(16, bufferLength);
}
static void compute(int bufferLength)
{
const __m128 two128 = _mm_set1_ps(2.0);
// floatを4つ同時に計算するため4で割る
// 即ちバッファの長さは4の倍数である必要がある
int bufferLength128 = bufferLength / 4;
// SIMD型にキャストする
__m128* zxBuffer128 = (__m128 *)zxBuffer;
__m128* zyBuffer128 = (__m128 *)zyBuffer;
__m128* cxBuffer128 = (__m128 *)cxBuffer;
__m128* cyBuffer128 = (__m128 *)cyBuffer;
for (int i = 0; i < N; i++)
{
for (int j = 0; j < bufferLength128; j++)
{
__m128 zx = zxBuffer128[j];
__m128 zy = zyBuffer128[j];
__m128 cx = cxBuffer128[j];
__m128 cy = cyBuffer128[j];
// SSEを使用して4つまとめて計算する
__m128 tx = _mm_mul_ps(zx, zx);
__m128 ty = _mm_mul_ps(zy, zy);
zxBuffer128[j] = _mm_add_ps(_mm_sub_ps(tx, ty), cx);
zyBuffer128[j] = _mm_add_ps(_mm_mul_ps(two128, _mm_mul_ps(zx, zy)), cy);
}
}
}実行結果は以下の通り3414msから1659msに約2倍程度高速化しています。
理想を言えば4倍程度になって欲しいのですが複素数をRGBに変換する処理などいくらかオーバーヘッドが発生しています。
SSE: enabled
Thread: 1
Width: 1024
Height: 1024
PixelRatio: 2.0
Step: 500
Time : 1659msSSEとpthreadの併用
さて、ではSSEとpthreadは同時に使えないものかと思い併用してみました。
ソースコードは省略しますがあっさりうまくいってしまい、3倍程度の高速化に成功しました。
SSE: enabled
Thread: 2
Width: 1024
Height: 1024
PixelRatio: 2.0
Step: 500
Time : 1083msChromeでは?
Google Chromeは残念ながらSSEもpthreadも対応していません。
ですがasm.jsには対応しているのでSSEやpthreadを無効にして実行してみたところ、
同じコンパイルオプションでFirefox Nightlyよりも良好なパフォーマンスを得ることができました。
JavaScript実行エンジンの違いでの差ということになります。
SSE: disabled
Thread: 1
Width: 1024
Height: 1024
PixelRatio: 2.0
Step: 500
Time : 2065msWebAssembly
本当はWebAssemblyでコンパイルしたかったのですが、以下のようなエラーがでていました。
Traceback (most recent call last):
File "/Users/yamada/emsdk-portable/emscripten/1.37.9/emcc", line 13, in <module>
emcc.run()
File "/Users/yamada/emsdk-portable/emscripten/1.37.9/emcc.py", line 1278, in run
assert not shared.Settings.USE_PTHREADS, 'WebAssembly does not support pthreads'
AssertionError: WebAssembly does not support pthreadsまだ、pthreadは対応していないようです。
まとめ
処理時間をまとめてみました。かなり効果的に高速化されています。
今後はSSEやpthreadを使った高速化に積極的に挑戦していきたいです。
| Firefox Nightly | SIMD及びマルチスレッド化なし | 3414ms |
| Chrome | SIMD及びマルチスレッド化なし | 2065ms |
| Firefox Nightly | マルチスレッド化 | 1952ms |
| Firefox Nightly | SIMD化 | 1659ms |
| Firefox | マルチスレッド化 + SIMD化 | 1083ms |
Firefox Nightlyは他の環境で試してみたところ処理するスレッドは1スレッドだったとしても、
pthread_createを使用してメインスレッドで処理せずに一つのサブスレッドで処理した場合のほうが高速だったこともありNightly Buildということもあり結果が安定していない印象を受けました。
と、ここまでSIMD推しできましたが直近ちょっとした事件が発生しました。
ECMAScriptの新仕様としてSIMDは議論が続けられてきましたがInactive Proposalに移動しました。
今後はWebAssemblyの一部としてSIMDの実装は続けられていくようです。
マルチスレッドやSIMDは従来はWebになかったチューニング手段です。
ゲームを始めとしてWebがプラットフォームとして育っていくのを見るとわくわくしますね。
参考
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。