
AWS Athenaを使ってみよう
KLab Advent Calendar 10日目の記事です。KLab分析基盤チームの高田です。
分析基盤チームでは、社内向けに各種KPIを提供している他、KG SDKのKPIレポートシステムを通じて、パートナー向けにシステムを提供しています。
今回は、先日re:Invent 2016で発表されたばかりのAWSの新サービスAthenaを試してみました。KLabの分析基盤システムでは、すでにRedshiftやEMRを使用していますが、Athenaには、これらを補うような役割(低コストで導入し、アドホックな分析や定型的なレポートの作成をサポートするといった用途)を期待しています。
Athenaとは?

ひとことで言えば、Athenaとは、S3上に置いてあるデータを高速にSQLで集計・分析できるサービスです。内部はPrestoをベースとしつつ、独自の改修をくわえて使用しているようです。Athenaの紹介としては、Amazon Web Serviceブログのこちらの記事も参考になるでしょう。
AWSでは以前より、EMRというサービスでHadoopやPrestoの機能を提供していましたが、Athenaでは自前でクラスタを組む必要なしに、クエリ検索機能を使用できます。なお、料金はクエリ量単位(5TBスキャンあたり$5)で設定されています。検索機能のみを提供するサービス形態や、課金形態はGoogleのBigQueryに似たものになっています。
複数のサービス・システム名が登場して複雑なので、以下に関連するサービスをまとめておきました。
| 名称 | 説明 | 提供者 |
|---|---|---|
| Hadoop | データの分散処理用のフレームワーク。 | Apache Software Foundation |
| Hive | Hadoop上で動くクエリエンジン。SQLベースの検索機能を提供。 | Apache Software Foundation |
| Presto | Hiveに似たクエリエンジン。Hadoop上でも動作するがそれ以外のデータソースも選択可能。 | |
| EMR | AWS上でHadoop/Prestoなどの分散システムを提供するサービス。 | Amazon |
| Athena | Presto相当の検索機能のみを提供。 | Amazon |
クエリ実行画面を試す
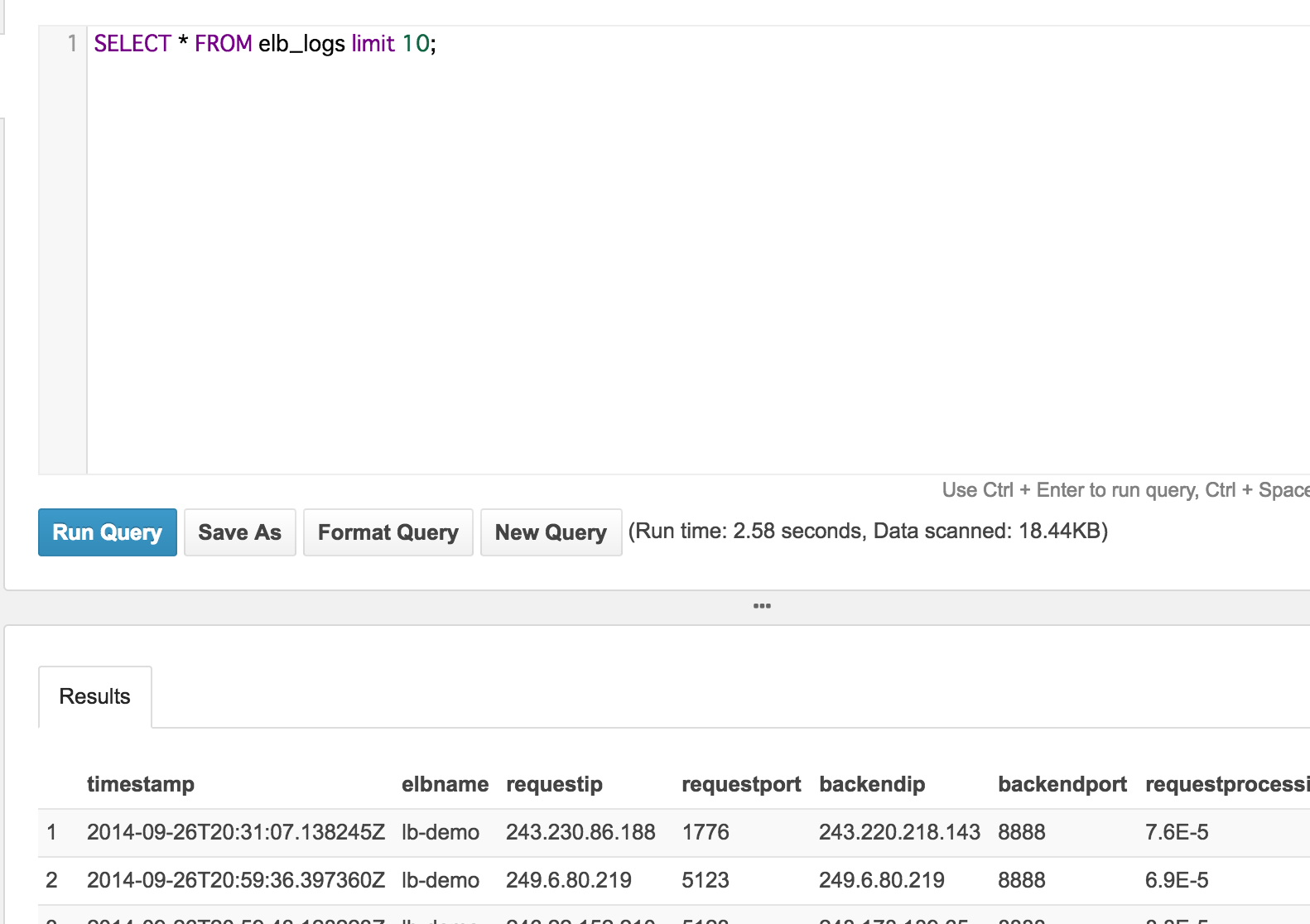
では早速クエリの実行を試してみましょう。sampledb というデータベースが最初から作成されており、クエリの実行をすぐに試すことができます。
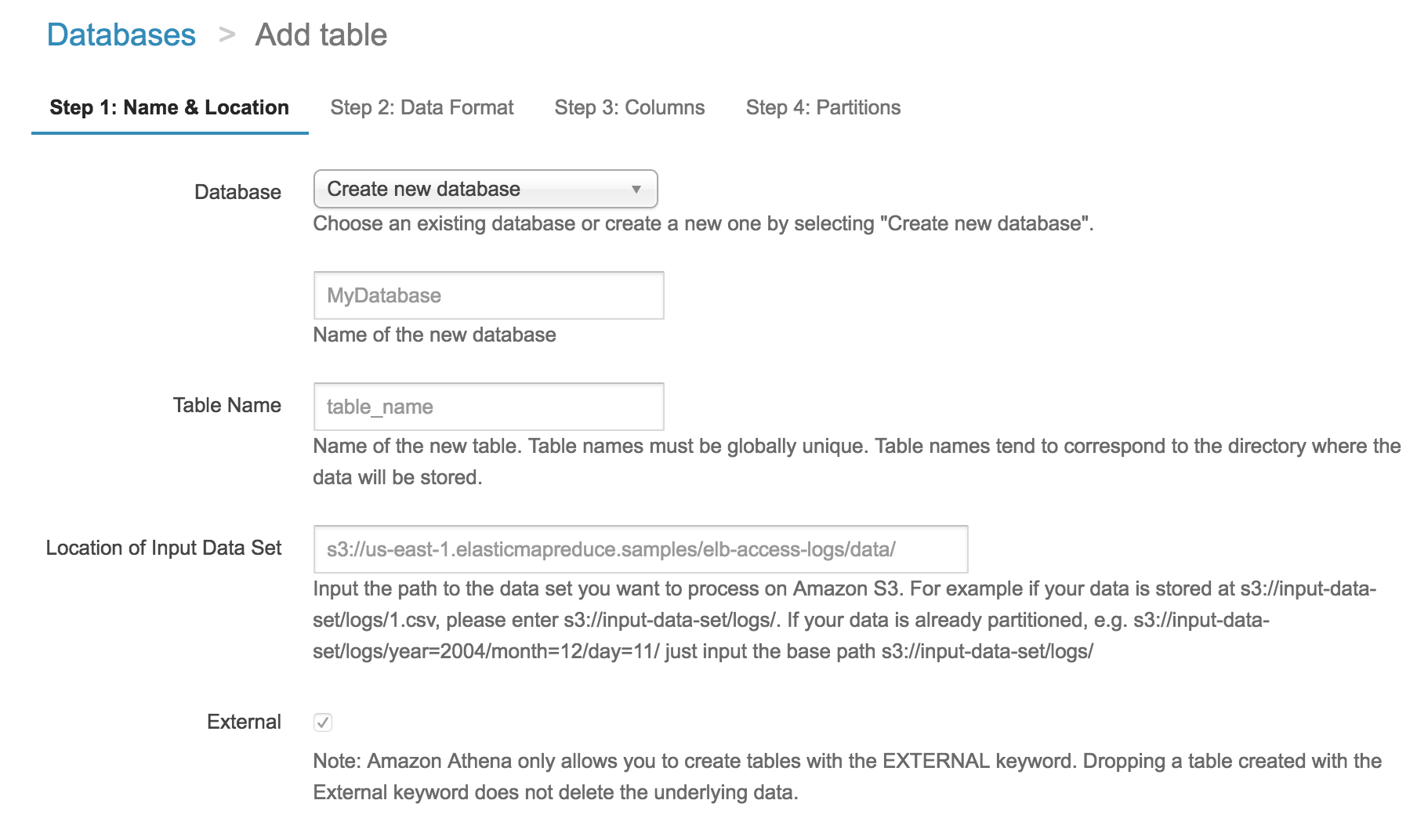
新しいデータベースやテーブルの作成も、Web画面から実行できます。
データ準備
現実的なユースケースでパフォーマンスを見たいので、自前のデータも準備し、普段の分析業務で使用するようなクエリを投げてみます。
KLabの分析基盤チームの場合、データの多くは、tsv形式でS3上に置かれています。これをそのまま検索対象にできれば理想的なのですが、残念ながら圧縮形式やディレクトリ構成の問題で、何も手をくわえずに検索対象にするということはできませんでした。
※Athenaの検索対象にするためには、ディレクトリ構成に一定のルールが必要です。また、圧縮形式としては、現状Snappy, Zlib, GZIPのみがサポートされているようです(FAQを参照)。
今回は以下の三種類のデータを用意しました。
| 種別 | 説明 | 1日分のファイルサイズ目安(gzip圧縮時) |
|---|---|---|
| dau | ゲームにアクセスしたユーザー | 数百KB |
| install | インストールしたユーザーのリスト | 数十KB |
| locale | ユーザーの国情報 | 数十MB |
それぞれ、S3上の以下のようなパスにアップロードしておきます。Athena用にカラム名を除外し、gzip圧縮しましたが、それ以外はごく普通のtsv形式です。データはすべて日別にわかれており、 dt=日付 というパスにアップロードします。それぞれ11月1日から12月5日までのデータをアップロードしてあります。この key=value というパス名は、Athenaにパーティションを認識させるためのルールになります。この形式にのっとらない場合は、手動でパーティションを追加する必要があります。また、パスはテーブルごとにわける必要があります。
s3://--bucket--/athena/dau/dt=2016-12-01/dau_2016-12-01.tsv.gzip
s3://--bucket--/athena/dau/dt=2016-12-02/dau_2016-12-02.tsv.gzip
...
s3://--bucket--/athena/install/dt=2016-12-01/install_2016-12-01.tsv.gzip
...
s3://--bucket--/athena/locale/dt=2016-12-01/locale_2016-12-01.tsv.gzipテーブル作成
あとは、Athena上でテーブルを作成するだけで、上記のファイルを検索対象とすることができます。
今回は以下のようなテーブルを作成します。テーブルの作成は、Web画面からも実行できるのですが、単純にCREATE TABLE文を実行するだけでも問題ありません。なお、ここでは dt (日付)をパーティションに指定しました。パーティションに指定したカラムは、SQL上で疑似的なカラムとして扱われるため、テーブル本体には同名のカラムを含めることができません。そこでテーブル本体の方の日付カラムには、 dtDontQuery という名前を設定しておきます。
ちなみに、テーブル定義はあれこれ試行錯誤していたのですが、テーブルスキーマがキャッシュされているのか、同名のテーブルをDROPしたあと、定義を修正して再度CREATE TABLEを実行しても、しばらくの間、古い定義が参照されてしまうという問題がありました。
CREATE EXTERNAL TABLE IF NOT EXISTS dau (
dtDontQuery date,
player_id string,
pv int
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ' ',
'field.delim' = ' '
) LOCATION 's3://--athena--/athena/dau/'CREATE EXTERNAL TABLE IF NOT EXISTS install (
dtDontQuery date,
player_id string,
datetime timestamp
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ' ',
'field.delim' = ' '
) LOCATION 's3://--athena--/athena/install/'CREATE EXTERNAL TABLE IF NOT EXISTS locale (
dtDontQuery date,
player_id string,
region string,
datetime timestamp
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ' ',
'field.delim' = ' '
) LOCATION 's3://--athena--/athena/locale/'S3上のパーティションを認識させるには、各テーブルについて以下のクエリを実行します。
MSCK REPAIR TABLE dau

パーティションが正常に認識されたかどうかは以下のクエリでパーティション一覧を表示することで確認できます。
SHOW PARTITIONS dau検索
いくつかクエリを実行し、性能を見てみます。残念ながらデータそのものはお見せできないのですが、以下、参考のため、クエリと実行時間を掲載しておきます。現状SQL上で使用できる関数なども、公式ドキュメントに記載がないため、やや試行錯誤が必要でした(ANSI SQLに準拠ということなので、ある程度は検討がつくのですが)。
今回追加したファイルのうち、このlocaleのデータがもっとも巨大です。全体で1.45GBほどあるのですが、単純なCOUNTクエリであれば6秒ほどで返ってきました(スキャン自体は行なっているようです)。
SELECT COUNT(*) FROM locale(Run time: 6.87 seconds, Data scanned: 1.45GB)
DAUを国別に集計してみます。これもlocaleのファイルが大きいためか、20秒ほどかかりました。
SELECT dau.dt, locale.region, COUNT(*)
FROM dau
JOIN locale
ON locale.player_id=dau.player_id
AND locale.dt=DATE('2016-12-05')
WHERE
dau.dt BETWEEN DATE('2016-12-01') AND DATE('2016-12-05')
GROUP BY dau.dt, region
ORDER BY dau.dt, region(Run time: 18.45 seconds, Data scanned: 45.54MB)
インストールユーザーの3日後の継続率を集計してみます。数秒です。
SELECT i.dt, COUNT(i.player_id) AS install,
COUNT(dau3.player_id) AS r3
FROM install AS i
LEFT JOIN (
SELECT player_id, dt
FROM dau
WHERE
dt BETWEEN DATE_ADD('DAY', 3, DATE('2016-11-01')) AND DATE_ADD('DAY', 3, DATE('2016-11-05'))
) AS dau3
ON dau3.player_id=i.player_id AND dau3.dt=DATE_ADD('DAY', 3, i.dt)
WHERE
i.dt BETWEEN DATE('2016-11-01') AND DATE('2016-11-05')
GROUP BY i.dt(Run time: 3.62 seconds, Data scanned: 3.65MB)
3日連続でログインしているユーザー数を出してみます。Athenaが苦手なクエリなのか、スキャン量が少ない割に1分半もかかっています。
SELECT t.dt, COUNT(*) as cnt FROM
(SELECT d.dt
FROM dau AS d
LEFT JOIN dau AS d2
ON d.player_id=d2.player_id
AND d2.dt>=DATE_ADD('DAY', - 2, d.dt) AND d2.dt<d.dt
WHERE
d.dt BETWEEN DATE('2016-12-01') AND DATE('2016-12-05')
GROUP BY d.dt, d.player_id
HAVING COUNT(d2.dt)=2
) t
GROUP BY t.dt(Run time: 1 minutes 28 seconds, Data scanned: 24.86MB)
こちらはサブクエリを使用するように書き変えることで大きく実行時間が変化しました。RedshiftやBigQueryと同じで、直接テーブルをJOINするのはあまり効率がよくないようです。参考のため、修正後のクエリも掲載しておきます。
SELECT t.dt, COUNT(*) as cnt FROM
(SELECT d.dt
FROM dau AS d
JOIN (SELECT player_id, dt FROM dau
WHERE
dt BETWEEN DATE_ADD('DAY', - 2, DATE('2016-12-01'))
AND DATE('2016-12-05')
) AS d2
ON d2.player_id=d.player_id
AND d2.dt >= DATE_ADD('DAY', -2, d.dt)
AND d2.dt < d.dt
WHERE
d.dt BETWEEN DATE('2016-12-01') AND DATE('2016-12-05')
GROUP BY d.dt, d.player_id
HAVING COUNT(d2.dt)=2
) t
GROUP BY t.dt(Run time: 4.34 seconds, Data scanned: 6.97MB)
以上のように、いくつかクエリの書き方で気をつけるべき点があるようですが、基本的には十分実用的な性能です。
Parquetへの変換
より効率のよいデータの格納方法として、AthenaではApache Parquetのような列志向のフォーマットもサポートされています(列志向フォーマット: データをカラムごとに格納するフォーマット)。Parquetへの変換方法として、公式ドキュメントで紹介されているHiveによる変換を試してみました(参照)。
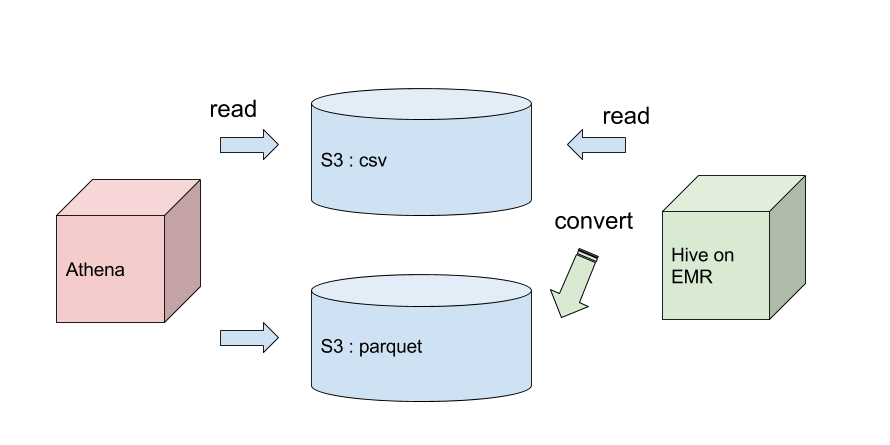
EMR上でHiveを立ち上げ、S3上のテーブルを読み込ませ、Hive上でテーブルをParquet形式に変換します。
まず以下のようなSQL(HiveQL)スクリプトを用意し、S3上に保存します(DAU以外のテーブルは省略してあります)。なお残念ながらParquet形式はDATE型に対応していないため、ここでは文字列に変換しています。また以下のクエリでは、ダイナミックパーティション(クエリ結果によってパーティションを決定する)を使用しているため、 最初の方にある hive.exec.dynamic.partition の設定が必要となります。
ADD JAR /usr/lib/hive-hcatalog/share/hcatalog/hive-hcatalog-core-1.0.0-amzn-5.jar;
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
CREATE EXTERNAL TABLE IF NOT EXISTS dau (
dtDontQuery string,
player_id string,
pv int
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ' ',
'field.delim' = ' '
) LOCATION 's3://--bucket--/athena/dau/';
MSCK REPAIR TABLE dau;
CREATE EXTERNAL TABLE p_dau (
dtDontQuery string,
player_id string,
pv int
)
PARTITIONED BY (dt string)
STORED AS PARQUET
LOCATION 's3://--bucket--/athena/parquet/dau/';
INSERT OVERWRITE TABLE p_dau PARTITION (dt) SELECT dtDontQuery, player_id, pv, dt FROM dau where dt BETWEEN '2016-11-01' AND '2016-12-05';awscliを利用し、Hiveを立ち上げて実行させます。
export REGION=us-east-1
export SAMPLEURI=s3://--bucket--/athena/dau/
export S3BUCKET=--bucket--
aws emr create-cluster --applications Name=Hadoop Name=Hive Name=HCatalog \
--ec2-attributes KeyName=kg-kpi-keypair,InstanceProfile=EMR_EC2_DefaultRole \
--service-role EMR_DefaultRole --release-label emr-4.7.0 \
--instance-type m1.large \
--instance-count 1 --steps Type=HIVE,Name="Convert to Parquet",\
ActionOnFailure=CONTINUE,ActionOnFailure=TERMINATE_CLUSTER,Args=[-f,\
s3://path/to/hive-script.q ,-hiveconf,INPUT=${SAMPLEURI},-hiveconf,OUTPUT=s3://${S3BUCKET}/athena/parquet,-hiveconf,REGION=${REGION}] \
--region ${REGION} --auto-terminateジョブの実行には1時間程度かかりました。ジョブの完了後S3を見ると、確かにファイルが作られています。つづけてAthena側でもCREATE TABLEを実行し、作成されたParquetファイルを認識させます。
CREATE EXTERNAL TABLE p_dau (
dtDontQuery string,
player_id string,
pv int
)
PARTITIONED BY (dt date)
STORED AS PARQUET
LOCATION 's3://--bucket--/athena/parquet/dau/';MSCK REPAIR TABLE p_dauParquet形式の場合、単純なカウントは、ファイルスキャンの必要がなくなるようです。
SELECT COUNT(*) FROM p_locale;(Run time: 2.95 seconds, Data scanned: 0KB)
SELECT dt, COUNT(*) FROM p_dau
WHERE
dt>=DATE('2016-12-01')
GROUP BY dt
ORDER BY dt(Run time: 0.99 seconds, Data scanned: 0KB)
ただし試した範囲では、スキャン量が増えてしまうこともありました。実行時間もものによっては改善しましたが、大きな変化が見られないケースが多いようです。以下、実行結果の比較をまとめておきます。
| 形式 | csv.gz実行時間 | csv.gzスキャン量 | Parquet実行時間 | Parquetスキャン量 |
|---|---|---|---|---|
| localeのCOUNT | 6.87s | 1.45GB | 2.95s | 0KB |
| 国別DAU | 18.45s | 45.54MB | 9.52s | 300.03MB |
| 3日後継続率 | 3.62s | 3.65MB | 2.69s | 12.33MB |
| 3日連続ログイン(修正前) | 1m28s | 24.86MB | 1m32s | 86.49MB |
| 3日連続ログイン(修正後) | 4.34s | 6.97MB | 3.28s | 24.39MB |
まとめ
Athenaを使用し、データ分析基盤で日常的に使用するような検索を試してみました。
以下は、触ってみた上での個人的な感想です。
- リリース直後ということもあり、サービスとしての完成度は、まだこれからの印象。ドキュメントなどはまだ不足しているように感じられた。
- 今後はAPIからの操作や、データインポート方法のバリエーションが増えることを期待したい。
- 一方、S3にテキストファイルを置くだけで使用できる気軽さや、値段の安さは魅力的。
- 性能も、定型レポートやアドホックな調査用途を想定すれば、十分実用的なもの。
KG SDKについて
KG SDKでは、データ分析基盤システムによるKPIレポートへの対応も行なっています。KG SDKの概要についてはこちら を、お問い合わせにつきましてはこちら をご覧下さい。
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。