
今夜勝ちたい CODE VS for STUDENT 攻略
(本稿はKLab Advent Calendar 2016 の9日目の記事になります)
こんにちは, @mecha_g3 です.
ISUCON6 の優勝賞金で新型の MacBookPro を購入しました. キーボードの打ち心地にどうも慣れられなかったり, USB-C の周辺機器がたくさん増えたりしていますが, 概ね満足しています.
格ゲーの攻略記事のようなタイトルですが, この1ヶ月ほど CODE VS for STUDENT というプログラミングコンテストに注力していたので, 今日はそれについて書きたいと思います.
CODE VS とは
CODE VS とは, お題となるゲームの, 最強のAIを開発するプログラミングコンテストです.
CODE VS for STUDENT 公式サイト https://student.codevs.jp
主催はチームラボさんとキャリフルさんで, KLabはスポンサーをさせて頂いてます.
決勝イベントが明日 12/10(土) に行われます. 決勝イベントでは, 予選で勝ち上がった学生 16 名 (Normalコース, Hardコース各8名) が対戦します.
また, 僕は学生を除いたランキングで 1 位だったので, エキシビジョンマッチに招待していただきました. 優勝した学生のAIと, 僕のAIが対戦します.
生放送もされるようなので, 是非観てください!
この記事の後半は, コンテストに参加していない方は興味がない内容になっているかもしれないので, 最初に宣伝しておきます.
ゲームのルール
今回のゲームは, CODEVS 2.0 のリメイク版で, 対戦形式の落ちものパズルです.
ルールの詳細は以下の PDF に記されています. https://student.codevs.jp/assets/files/rule.pdf
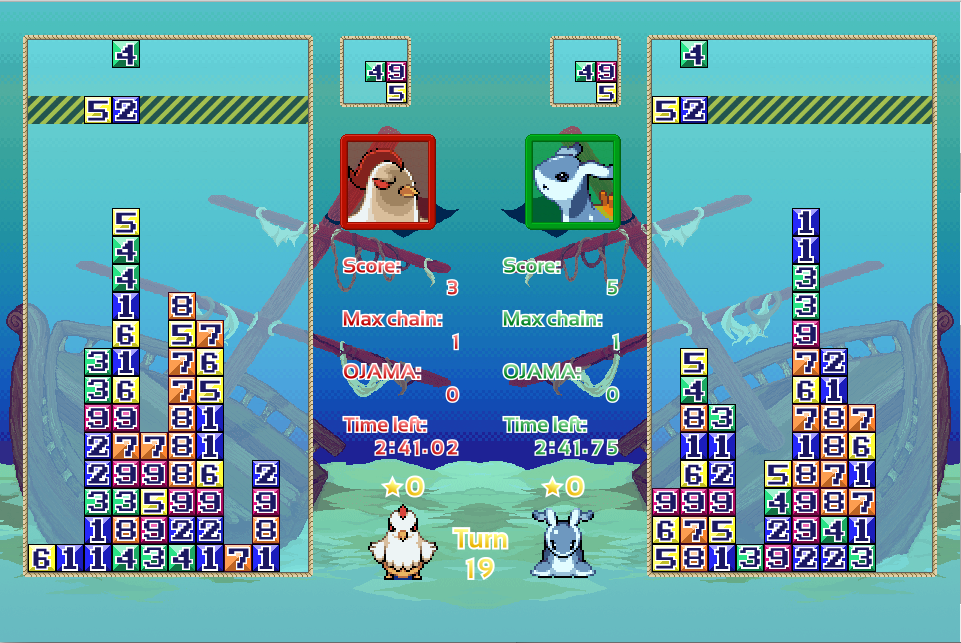
ゲームのリプレイ動画を撮影しました. 動画を見ると, ルールのイメージを掴みやすいです.
ブロック
1~9 の数字が書かれた 1x1 のブロックです.
パック
3x3 の領域にブロックが 3~4 個入っています. ゲーム開始時に全300ターン分のパックが与えられます.
フィールド
幅10, 高さ16 のフィールドで, ここにパックを投下していきます.
消滅と連鎖
フィールド上で 縦, 横, 斜めのブロックの数字の和が 10 になった所が消えます. 消えたブロックの上にブロックが積まれていた場合, 上のブロックが落下します. ブロックが消えた事により上のブロックが落下し, 落下したブロックが消える. という動作を繰り返し, 連鎖が発生します.
得点
連鎖を行うと、以下の得点計算式に従って得点を得ることができます.
score = ∑ floor(1.3 ^ i) * floor(Ei / 2)
i: 連鎖数
Ei: 消滅カウント(合計が 10 になったブロックの数)連鎖数に応じて指数的にスコアが上昇するので, 連鎖数が一番大事です. 連鎖の最後 (連鎖尾) の消滅カウントでスコアが数倍変わってくるので, 消滅カウントも無視できない存在です.
お邪魔ブロック
得られた得点に応じて, 相手にお邪魔ストックが加算されます. お邪魔ストックがある場合, パックの空いている領域にお邪魔ブロック (消すことができないブロック) が挿入されます.
自分にお邪魔ストックがある場合に得点を得た場合, お邪魔ストックが消費 (相殺) されます.
勝敗判定
パックがフィールドの外に溢れたり, 思考の制限時間を過ぎると敗北になります. 思考時間は 1 手最大 20 秒, 1 ゲームの持ち時間は 180 秒です.
基本的な考察
AIのプログラムは, 標準入力でゲームの情報を取得し, 各ターンにおいてパックを何回転させてどこに投下するかを標準出力に出力します.
全ターンのパックは事前に分かるので, 落下と連鎖のシミュレーションを行い, 大連鎖を作ることを目標に探索するプログラムを作る事になります.
長いターン使って大連鎖を作ろうとしていると, 相手が先に連鎖を発火し, 邪魔ブロックが降って来て大連鎖を発火できずに負けてしまいます.
逆に, 短いターンで連鎖を作っていると低いスコアになってしまい, 相手に邪魔ブロックが大して降らないため, 相手は連鎖を伸ばすことができてしまいます.
そこそこ短いターンで出来るだけ大きな連鎖を作る探索が, このゲームで一番大事なポイントです.
ここからは, 僕がこの探索部分をどう改良していったかについて掘り下げていきます.
アプローチ
落とし方は 1ターンあたり 48 通りあるので, 4 ターン先(48^4 = 5308416) まで調べるのに数秒かかりそうです.
実際には有効な落とし方はもう少し少ないですが, 全探索だと 5, 6 ターンが限界だと思います.
相手のフィールドを埋め尽くす程の邪魔ブロックを降らせるためには, 16 ~ 20 連鎖程度必要で, そこから考えると 20 ターン程度必要です.
このような探索の問題では, 評価関数を作り, 各深さ毎に評価値の高い上位 K個 を残すことを繰り返すビームサーチという手法がよく使われます. (K をビーム幅と呼びます)
もちろん厳密な解は得られませんが, 適切な評価関数が設定できれば, 短い時間でそこそこ良い解を得ることができます.
僕は最初ビームサーチで実装していましたが, 今回の問題では時間制限がシビアだったので, 時間調整のしやすいビームサーチの亜種である chokudaiサーチを採用しました.
ベンチマーク
探索の改良を試したり, 評価関数を調整した結果, それが良くなったか悪くなったかを比較できるようにする必要があります.
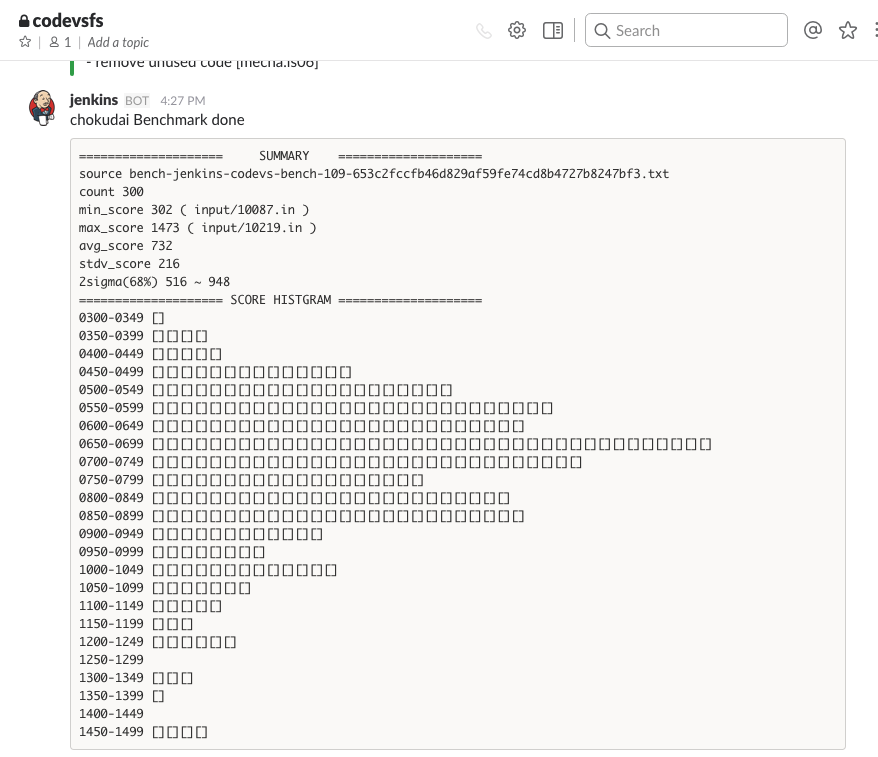
今回僕は, 公式クライアントから 300 ゲームの入力ファイルを抽出し, 各入力で 20 ターン先まで探索し, できた連鎖のスコアの平均値を見て調整しました.
1 回 15 秒かけて探索するので 1 時間半かかってしまいますが, Google Compute Engine で 16 コアのマシンを借りて並列で走らせる事で 5 分程で計測することができるようになりました.
GCE 上に Jenkins をインストールしたプリエンプティブインスタンスを用意し, ベンチマークをかけたい時だけ立ち上げて実行, 終わったら個人的に使っている slack に結果を通知し, インスタンスを停止する. という運用で使っていました. 今回 CODE VS のために使った金額は 400 円程度でした.
評価関数
「連鎖数が大きくなるようにしたい」というのはどういう評価関数にしたら良いのか悩みどころですが, 評価関数の中で実際に連鎖を起こしてみて何連鎖したのかを見るのが簡単です.
各列に対して 1-9 のブロックを落とすシミュレーションをしてみると, 何連鎖する盤面なのかを正確に見積もることができます.
ただ, 1 状態を評価するのに 90 回もシミュレーションをするのはとても無駄が多く遅いので, ある程度サボらないといけません.
僕の場合は, フィールドを広く使って, 左端から右端(あるいは右端から左端) に向かって連鎖を伝搬させていくような積み上げ方を見つけて欲しかったので, 発火点を左端か右端に固定しました.
最初の評価関数は
200 * 左端の列に 4 を落としたときに発生するスコア + 連鎖前のブロック数でした. すごく雑ですが, わりと強くて最初の 1 週間程度 1 位を維持していました.
ここから, ベンチマークの結果を見ながら評価関数を調整していきました.
最終的には
ランダム(0.0 ~ 1.0)
+ 100000 * 連鎖数
+ 1000 * 連鎖前のブロック数
+ 10 * 連鎖尾の消滅カウント
- 100 * 連鎖あたりの平均消滅ブロック数
- 1 * 連鎖後に残っているブロック数としました.
お邪魔ブロックが混入してきた場合は発火に使うブロックを 1-9 で試すようにしましたが, 他は同じです.
各パラメータの重みは比較の優先度を決めているだけです.
ランダム
連鎖数が増えるまでの盤面は優劣をうまく付けれないので, 同じスコアが並びやすいです.
同じスコアが並んだ場合, 特定の順序 (探索キューに入れた順など) で偏りが出てしまうので, これを分散させる目的で入れています.
連鎖数
発火目標ターンのパックをフィールドの端に落とした際に発生する連鎖数です.
この方法で評価した場合, 発火点は固定なので, 連鎖尾を伸ばしていくような探索になります.
スコアをそのまま評価関数にしてしまうと, 連鎖数を伸ばすよりも同時消し数を増やしてしまうほうが良いと評価してしまうことになるので, 最終的に連鎖が伸びにくくなってしまいます.
連鎖前のブロック数
フィールド中に存在する, お邪魔ブロックを除いた 1-9 のブロックの数です.
連鎖を積み上げていく途中で, 無駄に消してしまうとそれだけでもったいないので, ブロック数が多い方が良い状態としました.
連鎖尾の消滅カウント
連鎖尾も一応評価したいのですが, それよりも連鎖数を伸ばして欲しいので評価値としてはかなり優先度を低くしてあります. 気持ちです.
連鎖あたりの平均消滅ブロック数
連鎖で消えたブロック数 / (連鎖数+1) で計算しています.
限られた数のブロックで大きな連鎖を作って欲しいので, 同時消しが多いのは無駄です. 連鎖あたりの平均消滅ブロック数が少ないほうが良い状態としました.
連鎖後に残っているブロック数
8 や 9 といった大きい数字のブロックは 1 や 2 が来ないと消えません. 一方 1 や 2 は他の数字のブロックとも消えます. 連鎖が終わった後で 8 や 9 が残りやすく, これが実質的にお邪魔ブロックになって次回連鎖のスコアが下がってしまう現象が見られたのでこれを入れました.
高速化
速い方がたくさんの盤面を探索できるので, 制限時間内に良い連鎖を見つけやすいです.
テストの作成
シミュレータのテストがあると安心してリファクタリングや高速化に着手できます.
今回のルールでは, CODEVS のクライアントのリバースエンジニアリングは禁止されていませんでした.
クライアントの jar をライブラリとしてインポートした Java プロジェクトを作る一般的なテクを用いて, ログファイルから入出力を抽出するプログラムを作りました.
オンライン対戦のログファイルを大量に用意し, そこから入出力を作ってテストケースとしました.
評価用の落とし方の固定
ある程度探索が進むと, 発火に使うパックの落とし方はほぼ決まってしまうので, 評価関数の中で色々な落とし方を試して評価するのは無駄が多いです. なので, 4 連鎖以上が発生した場合は, 次から評価関数内での連鎖数の評価に使うパックを固定するようにしました.
精度は落ちますが, かなり無駄が省けるのでスコアは上がりました.
同一盤面の除去
高速化とは少し違う話ですが, 一般的に探索の途中で同じ盤面を 2 回探索しないようにするのは多くの場合必須な処理です. これを同一盤面の除去と呼んでいます.
今回はゲームの性質上, 完全におなじフィールドは現れにくいので効果は薄いですが, 探索中のフィールドをビジュアライズしてみると, 少なからず現れていたので除去を行いました.
フィールドのハッシュ値を計算し, 探索済のハッシュ値を保持しておきます. 同じハッシュ値のフィールドが現れた場合, 処理をスキップします.
探索のキューに入れるタイミングではなく, キューから取り出すタイミングで判定することでほとんどコストをかけずに除去することができます.
同一盤面を除去することで, 多少ですが無駄な探索を減らす事ができました.
落下処理の高速化
予選の対戦サーバは Xeon E5-2670 v2 だったのですが, 決勝参加者向けに提供された環境は Xeon E5-2666 v3 でした. (おそらく c4.large)
調べた所 v3 では Haswell 世代の命令が使えます.
Haswell から使える命令に PEXT (Parallel bits extract) という命令があります. これは値 val と ビットマスク mask を入力し, val のビット列の中から mask 指定したビットを抽出し, それを下位ビットに寄せたビット列を作る命令です.
さて, ブロックの数字は 0~11 (お邪魔ブロックは11で表される) なので 4bit あれば表現でき, フィールドは幅10 高さ16なので, 64bit 整数 10 個で表現することができます.
このようにフィールドを表現すると, PEXT を消去が行われた列に対して使うだけで落下処理が実装できます.
// erased_y_mask := 消えたブロックの位置が 1111 となるようなビットマスク
// m_[x] := 1列を表す uint64_t 型の変数
m_[x] = _pext_u64(m_[x], ~erased_y_mask);落下処理のために生まれたかのような命令ですね.
消去処理の高速化
消去処理では, フィールド中にある隣接したブロックの数字の和が 10 になる場所を探さなければなりません.
和が 10 になるかどうかの計算は, しゃくとり法というテクニックを使うことで, 各列に対して 1 度走査するだけで行うことができます.
あるブロックが落下した結果, そのブロックに隣接したブロックの数字の和が 10 になることで消去が発生するので, 落下が発生していない領域は調べる必要がありません.
落下が発生した行, 列と, それに対応する斜めの行を記録しておき, 消去が発生しえない範囲に対しては消去判定を行わないようにしました.
もう少し具体的に説明すると, あるブロックが落下し (x, y) で止まったとしたとき, 以下のビットマスクをつくります.
x_mask |= 1 << x
y_mask |= 1 << y
z_mask |= 1 << (x + y)
w_mask |= 1 << (9 - x + y)x_mask, y_mask はそれぞれ縦消し, 横消しが発生する可能性のある列を表します.
z_mask, w_mask はそれぞれ左上から右下, 左下から右上に向かっての斜め消しが発生する可能性のある列を表します.
ビットが立っている縦, 横, 斜めだけを調べ, さらに横と斜めは x_mask によって調べる範囲を絞ることができます.
これらの評価関数の調整や高速化により, 20 ターン発火での平均得点は 400 点程度から 730 点程度まで上がりました.
また, 20 ターン発火では火力不足で負けてしまう事があったので, 最終的には 22 ターン発火にしました. 22 ターンでは平均 1070 点程になりました.
今夜勝ちたい実装
エキシビジョンマッチ向けに実装した勝ちたいだけのちょっとズルい実装です.
ルール的に禁止していないことを確認した上で実装しています.
相手の思考時間を使う
ゲーム開始直後の 1 ターン目で 22 ターン先まで探索して落とし方をキューに入れておき, その後は邪魔ブロックが降ってこない限り, キュー入れた落とし方を再生するような実装になっています.
相手が 1 ターンあたり 1 秒つかって探索してくるタイプの場合, 20 秒程 CPU が暇することになります.
なので, キューの内容を再生中も裏で探索を継続しておき, よりよい連鎖が見つかったら途中で乗り換えるという実装をしました.
相手に合わせて発火ターン数を調整する
十分にダメージが与えられる量のお邪魔ブロックを送ることができるなら, 先に発火したほうが勝ちやすいルールになっているように思います. なので, 対戦時のログをファイルに記録しておき, 以下のルールに従って初回攻撃のターンを調整する機能を実装しました.
前回の対戦で勝利した場合
- 前回の初回攻撃のターンを使用する
前回の対戦で敗北した場合
- 相手の方が先に初回攻撃を行っていたら, 相手の初回攻撃ターンでこちらも初回攻撃を行う
- 自分の方が先に初回攻撃を行っていたら, 初回攻撃ターンを +1
ボツネタ
考えたけど上手く行かなかった事, 実装できなかったことなどです.
発火点を成長させる
連鎖を組んでいく際に, 発火点を成長させるのと, 連鎖尾を成長させるのでどちらが強いのでしょうか.
当たり前のことですが, 上から落下させたブロックは, 下から上に積み上がっていきます.
発火点を固定し, 連鎖尾を成長させる場合, 発火点は必然的にフィールドの下の方になってしまいます. フィールドの下の方でブロックを消すと, 上に乗っているたくさんのブロックが落下し, 多くのブロックがズレることになります. たくさんのブロックズレるということは, たくさんのブロックが消える可能性があるわけですが, 連鎖数を稼ぎたいので, 同時消しではなく 2, 3 個ずつ消えて欲しいです. 一度ズレたけど消えなかったブロックは, 今後同様のズレの状態になったとしても消えません.
この消えないズレの組み合わせが徐々に連鎖の成長を制限するため, 連鎖尾を成長させる方針はある程度で頭打ちになります.
発火点を成長させていくと, 発火点が上になるためこの制限を受けづらくなり, フィールド全体を使って連鎖を作ることができます.
ズレの理論に関しては, CODE VS 2.0 の colun さんの説明がわかりやすいです.
また, 連鎖尾の同時消しはスコアにそこそこ大きな影響を与えます. 発火点を伸ばす場合, 連鎖尾の同時消しを作った後に発火点を伸ばすことができるので, 高いスコアを取りやすいと考えられます.
つまり, 発火点を成長させる方針は, 以下のようなメリットがあります.
- フィールド全体を使って大連鎖を作ることができる
- 連鎖尾の同時消しを作ることができる
一方で, 連鎖尾を伸ばす連鎖は, 以下のようなメリットがあります.
- 少ないブロックで柔軟な連鎖を組みやすい
- 発火点を固定することで評価が高速にできる
- 邪魔ブロックが降ってきても発火点さえ潰れなければ連鎖は残る
CODE VS 2.0 予選では発火点を成長させる連鎖が強かったのですが, 今回の CODEVS for STUDENT では, スコアに対して相手に送る邪魔ブロックの数が多く, 素早く連鎖を作ることが大事だったため, 連鎖尾を伸ばす方針にしました.
マルチスレッド化
CPU を使い切るために, 探索をマルチスレッドで動かす実装を行いました.
できるだけロック時間が減るように探索の仕方を工夫し, 手元の PC では 2 スレッドにした際に約 2 倍探索できるようになりました.
しかし, 決勝の環境はハイパースレッディングの 2CPU だったので, 1 スレッドと比べて 1.2 倍程度にしかなりませんでした.
プログラムが複雑になってしまったのと, 探索順序が実行するたびに微妙に変わってしまい, 他のチューニングがやりにくくなってしまったので破棄しました.
ベクトル演算による高速化
連鎖のシミュレーションのうち, 一番ボトルネックになるのは, 加算や減算をたくさんして部分和が 10 になるところを探す消去判定です.
加算や減算をたくさんするので, ベクトル演算を使いまとめて演算を行うことで高速化できるはずだと考えて, 3 日ほど AVX2 の関数の使い方を覚えベクトル演算版のシミュレータを書きました.
消去判定のしゃくとり法において, 10 を超えた部分に関して戻って減算をする部分でどうしても演算回数を減らすことができず, 影響範囲のあるところだけ調べるナイーブなしゃくとり法に比べ, 1/3 程度の速度しか出せませんでした.
もっとベクトル演算に慣れて, ベクトル演算しやすいアルゴリズムを思いついたら速くなるかもしれませんが, 今回はあきらめました.
評価関数の自動調整
各評価パラメータの重みが, 比較優先度を決めているだけになってしまいました.
ブロックの位置関係など, もう少しパラメータを増やし, 重みを機械学習的な手法での自動調整に挑戦してみたかったです.
僕が今夜勝ちたいだけの実装をしている間に, 決勝に出場する piroz さんはこの自動調整に挑戦していたらしく, とても尊敬しています.
結果的にうまく調整できなかったようですが, コンテストを通しての成長という観点で僕は完全に負けています.
pirozさんの記事
ソースコード
エキシビジョン提出時のソースコードを公開します.
後に気づいたバグがそのままだったり, 人に読ませるつもりのない思考ログやコミットログが残っていますが, コンテスト参加時のリポジトリをそのまま公開します.
https://bitbucket.org/mecha_g3/codevsfs/src
まとめ
明日は CODEVS for STUDENT の決勝イベントが行われます. エキシビジョンマッチで僕の今夜勝ちたいAIが優勝者と対戦します.
生放送是非観てください!
2017年は機械学習勉強するぞ!!!!
@mecha_g3
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。