
gitベースでアセット管理システム(もどき)を作る
こんにちは。@kokukumaです。
みなさんは画像や音声データなど(以下、アセット)をどのように管理しているでしょうか?
簡単なversion管理ツールを使っている人もいれば、専用のアセット管理ツールを導入している人もいるでしょう。
私がいま在籍しているプロジェクトでは、他のクライアントコードと同様にgitで管理していました。
しかし、プロジェクトが進むにつれてアセットも増え、gitでは辛い場面も数多くでてきました。
- cloneが遅すぎる。実行して一晩寝かせるレベル。
- 容量がでかすぎる。12GBとかある...。消したい。
- ふざけるな。git fetchが遅すぎる。
というような状態になり、やっぱりアセットをgitで管理するのは無理があるよねとなりました。
しかし、今から別のツールに移行するのも結構辛い。。
という事で、gitを使いつつ、もっと簡単にアセット管理をできる仕組みを考えてみました。
こんなのを作ることにした
クライアント-アセットの対応情報を取得できる
クライアントとアセットの整合性が取れていなければ、動かない可能性があります。
そのため、自分が開発しているクライアントに対応するアセットがどれかを知る必要があります。
それを保存するためにDBとかを準備するのが面倒なので、gitレポジトリの中に保存してしまうことにしました。
そして、この情報のみ頻繁にfetchするようにします。
必要最小限のアセットだけfetchする
一度に使うのは、特定のversion, 特定のplatform用のアセットです。
そのため、上記の対応情報でわかったアセットだけを取得します。
もちろん履歴はfetchしません。加えて、必要なplatformのディレクトリだけfetchする形にしました。
これによって、実際のアセットを取得する際も、それほど時間をかけずに取得できます。
全体像を書くとこんな感じです。
図1. アセット管理の流れ
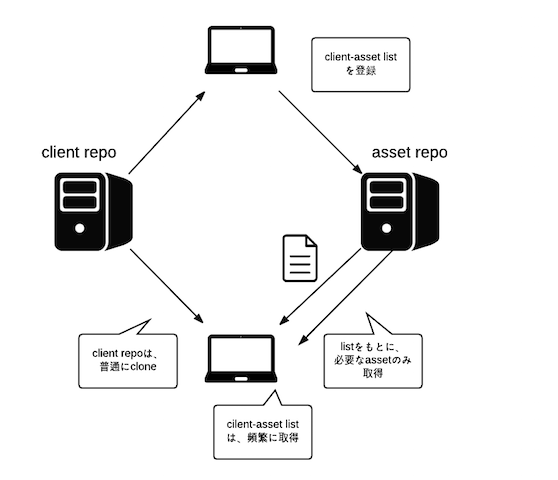
これで、fetchが重いとかローカルの容量が大きくなりすぎるといった問題を回避できそうです。
これらをどうやってgit上で行っているかを説明するために、gitの内部構造について軽く触れておきます。
gitの内部構造
『Pro Git』Chapter 10「Gitの内側」を読むと、Gitの中でどのように変更履歴やディレクトリ構造が保存されているのかがよくわかります。
要点をまとめると以下になります。
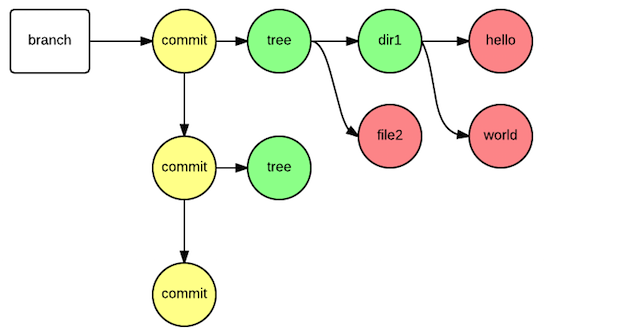
- 変更履歴・ディレクトリ構造は、commit object, tree object, blob objectのグラフで表現されている。
- tree objectには、ディレクトリ中にある、ディレクトリ名やファイル名が保存される。
- blob objectには、ファイルのコンテンツが保存される。
つまり、dir1/hello、dir1/world、file2と3つのファイルが保存されている場合、以下の様に保存されることになります。
図2. gitの構造
クライアント-アセットの対応情報を取得する
gitの内部がこのような形であると分かれば、レポジトリに保存されているディレクトリ構造と関係なく、データを保存して置けることがわかります。
gitの配管コマンドを利用すれば、ファイルを作成・編集しなくても、indexファイルにデータを書き込みcommit objectを作成することが出来ます。
そして、tree構造を作ってしまえば、gitのコマンドを使って簡単に保存した値を取得することができます。
つまり、tree objectの構造をkeyとして、blob objectにvalueを保存する、簡単なkey value storeとしてgitレポジトリを利用することができるわけです。
以下、bashでこの操作をやるとこんな感じです。
# set_value (レコード名) (key) (value) .gitディレクトリで実行。
set_value refs/heads/ppack_index/record1 assets/iphone ppack_assets_3dd0_iphone
# get_value (レコード名) (key) .gitディレクトリで実行。
get_value refs/heads/ppack_index/record1 assets/iphone
# => ppack_assets_3dd0_iphone
function set_value(){
export GIT_INDEX_FILE='tmp_index'; # まっさらなindex
local RECORD=$1
local KEY=$2
local VALUE=$3
local PARENT=""
# 指定したレコードが既にあればそれをindexに読み込む。
if [[ ! -z $(git show-ref $RECORD) ]]; then
git read-tree $RECORD^{tree}
PARENT="-p $RECORD"
fi
BLOB_HASH=$(echo ${VALUE} | git hash-object -w --stdin) # valueを保存したblob objectを作成。
git update-index --add --cacheinfo 100644 $BLOB_HASH $KEY # keyをファイル名としてindexに登録。
TREE_HASH=$(git write-tree) # 今のindex内容でtree objesctを作成する。
COMMIT_HASH=$(git commit-tree $TREE_HASH -m $RECORD $PARENT) # treeにcommit objectを紐付ける。
git cat-file -p $COMMIT_HASH^{tree}
# RECORDブランチを作成
git update-ref $RECORD $COMMIT_HASH
rm tmp_index
unset GIT_INDEX_FILE
}
function get_value(){
local PPACK_INDEX=$1
local KEY=$2
VALUE=$(git cat-file -p $PPACK_INDEX:$KEY 2> /dev/null) # あるcommitのファイルの中身を
echo $VALUE
}この中に、clientレポジトリのコミットと、それに対応する必要最小限のアセットを指定するコミットを紐づけるデータを保存しておきます。
1つのレコードには、以下の情報を登録しておきました。
| key | value |
|---|---|
| client_branch | クライアントのブランチ名 |
| client_commit | クライアントのコミットhash |
| asset_commit | assetのコミットhash |
| assets/iphone | iphoneのアセットだけ取得するためのコミット |
| assets/android | androidのアセットだけ取得するためのコミット |
次に、iphone/androidだけを取得するコミットをどうやって作るかを説明します。
必要最小限のアセットだけfetchする
私の案件では、platform毎にディレクトリが分けられ、アセットが保存されていました。
そのため、必要最小限のアセットだけをfetchするためには、特定のディレクトリだけfetchする方法が必要です。
それを実現するために、clone/fetchするobjectがどのようにして選ばれるかを調べ、利用しました。
まず、通常cloneすると、図2のようにブランチが示すcommit objectから辿れる全てのオブジェクトを取得します。
一方、shallow cloneを実行すると、図3のように、履歴をたどらずに取得することができます。
図3. shallow cloneしたとき(赤黄緑だけcloneする)
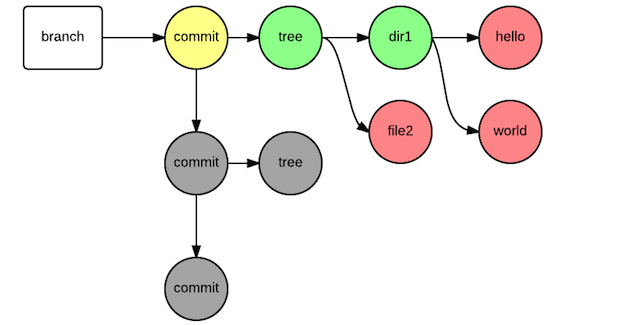
ここから、clone/fetchする対象は、指定されたcommit objectとから辿ることが出来る範囲にしぼられることが分かります。
そのため、ディレクトリ単位でfetchするためには、cloneしたいディレクトリのtree objectを指すcommit objectを作ってやり、それをcloneの対象として指定すればよいことになります。
図4. ディレクトリ単位でgit cloneする時の図(赤黄緑だけcloneする)

以下、bashでこの操作をやるとこんな感じです。
# clone元レポジトリで事前にやっておくこと。
declare BASE_HASH="692c6c9"
declare TARGET_DIR="directory_name"
TREE_HASH=$(git rev-parse $BASE_HASH:$TARGET_DIR)
COMMIT_HASH=$(git commit-tree $TREE_HASH -m 'clone')
git tag -a clone_tag -m 'clone_tag' $COMMIT_HASH
# cloneするときの操作
git clone -b clone_tag (clone元レポジトリのurl)このアセットfetch用のcommit objectを、クライアントのコードに対応するアセットとして情報を持っておけば、必要最小限のアセットを取得することができるようになります。
まとめ
gitの構造を利用してやることで、ファイル数が多すぎて重いレポジトリでも、負荷なく使える環境を作ることができました。
今後、もう少し汎用的なツールにまとめていきたいです。
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。
おすすめ
合わせて読みたい
このブログについて
KLabのゲーム開発・運用で培われた技術や挑戦とそのノウハウを発信します。